0X01理论
卡顿原理:
目前主流移动设备均采用双缓存+垂直同步的显示技术。大概原理是显示系统有两个缓冲区,GPU会预先渲染好一帧放入一个缓冲区内,让视频控制器读取,当下一帧渲染好后,GPU会直接将视频控制器的指针指向第二个容器。这里,GPU会等待显示器的VSync(即垂直同步)信号发出后,才进行新的一帧渲染和缓冲区更新。
大多数手机的屏幕刷新频率是60HZ,如果在 1000⁄60=16.67ms 内没有将这一帧的任务执行完毕,就会发生丢帧现象,这便是用户感受到卡顿的原因。这一帧的绘制任务包括CPU的工作和GPU的工作两部分,CPU负责计算显示的内容,例如视图创建、布局计算、图片解码、文本绘制等等,随后CPU将计算好的内容提交给GPU,由GPU进行变换、合成、渲染。
除了UI绘制外,系统事件、输入事件、程序回调服务、以及我们插入的其它代码也都在主线程中执行,那么一旦在主线程里添加了操作复杂的代码,这些代码就有可能阻碍主线程去响应点击、滑动事件,以及阻碍主线程的UI绘制操作,这就是造成卡顿的最常见原因。
在了解了屏幕绘制原理和卡顿形成的原因后,很容易想到通过检测FPS就可以知道App是否发生了卡顿,也能够通过一段连续的FPS帧数计算丢帧率来衡量当前页面绘制的质量。然而实践发现FPS的刷新频率非常快,并且容易发生抖动,因此直接通过比较通过FPS来侦测卡顿是比较困难的。而检测主线程消息循环执行的时间就要容易的多了,这也是业内常用的一种检测卡顿的方法。因此,Hertz在实践中采用的就是检测主线程每次执行消息循环的时间,当这一时间大于阈值时,就记为发生一次卡顿。
--https://tech.meituan.com/2016/12/19/hertz.html
造成卡顿的问题很多,最常见的就是主线程负担过重,cpu占用随之变高。那么检测主线程的状态这个思路就比较合理了。
0x10方案总结
这里主要介绍下检测卡顿的几种方案。
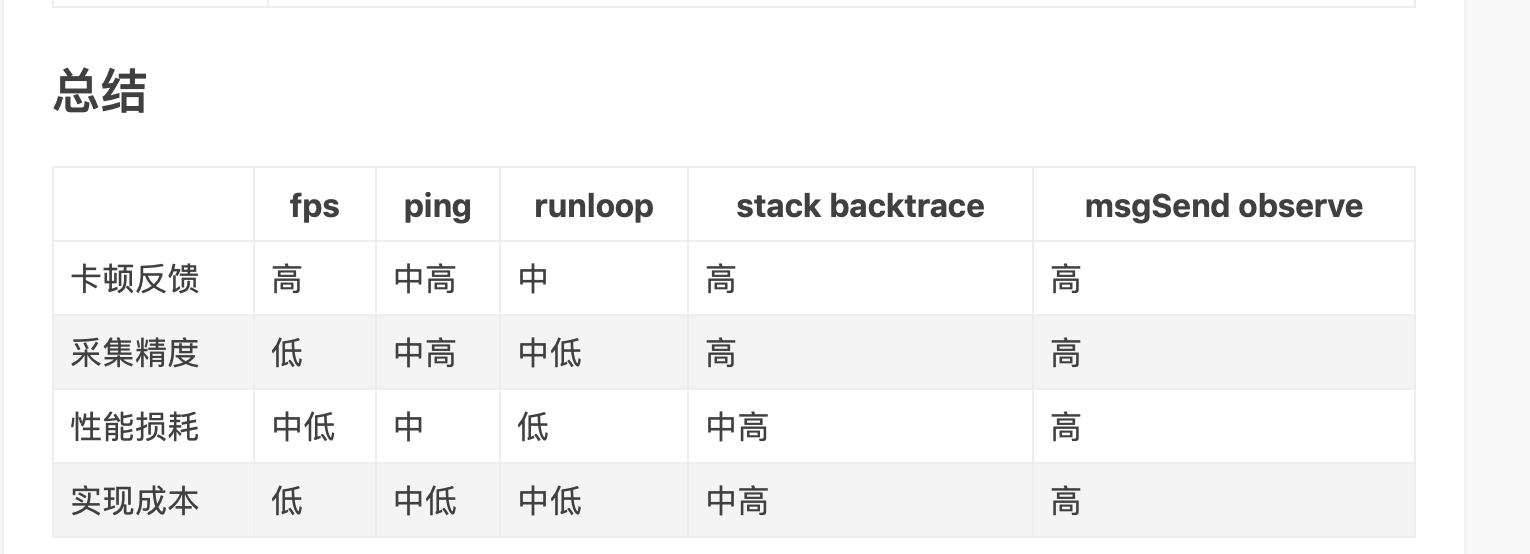
fps:
方法简单 好理解 好实现,对应精度也不怎么高 可以作为辅助检测。
ping:
runloop:
最主流的检测方案,bugly 、戴铭的GCDFetchFeed 、MTHawkeye 美团等。
CPU:
同时,我们也认为 CPU 过高也可能导致应用出现卡顿,所以在子线程检查主线程状态的同时,如果检测到 CPU 占用过高,会捕获当前的线程快照保存到文件中。目前微信应用中认为,单核 CPU 的占用超过了 80%,此时的 CPU 占用就过高了。
— by https://cloud.tencent.com/developer/article/1427933
戴铭在GCDFetchFeed中如果CPU 的占用超过了 80%也捕获函数调用栈,以下是代码:
#define CPUMONITORRATE 80
+ (void)updateCPU {
thread_act_array_t threads;
mach_msg_type_number_t threadCount = 0;
const task_t thisTask = mach_task_self();
kern_return_t kr = task_threads(thisTask, &threads, &threadCount);
if (kr != KERN_SUCCESS) {
return;
}
for (int i = 0; i < threadCount; i++) {
thread_info_data_t threadInfo;
thread_basic_info_t threadBaseInfo;
mach_msg_type_number_t threadInfoCount = THREAD_INFO_MAX;
if (thread_info((thread_act_t)threads[i], THREAD_BASIC_INFO, (thread_info_t)threadInfo, &threadInfoCount) == KERN_SUCCESS) {
threadBaseInfo = (thread_basic_info_t)threadInfo;
if (!(threadBaseInfo->flags & TH_FLAGS_IDLE)) {
integer_t cpuUsage = threadBaseInfo->cpu_usage / 10;
if (cpuUsage > CPUMONITORRATE) {
//cup 消耗大于设置值时打印和记录堆栈
NSString *reStr = smStackOfThread(threads[i]);
SMCallStackModel *model = [[SMCallStackModel alloc] init];
model.stackStr = reStr;
//记录数据库中
[[[SMLagDB shareInstance] increaseWithStackModel:model] subscribeNext:^(id x) {}];
// NSLog(@"CPU useage overload thread stack:\n%@",reStr);
}
}
}
}
}
0x11实战
一个图片加载引起的好奇
2019-09-07 15:02:59.714920+0800 ModuleStockExample[99873:5594540] Alice: 3| 133.48 ms| +[UIImage imageNamed:inBundle:compatibleWithTraitCollection:]
2019-09-07 15:02:59.715031+0800 ModuleStockExample[99873:5594540] Alice: 2| 133.94 ms| +[UIImage gjbase_imageNamed:]
2019-09-07 15:02:59.715143+0800 ModuleStockExample[99873:5594540] Alice: 1| 134.88 ms| -[MarketViewController setBackBtn]
方法使用不是最优的,需要极致的工匠精神
感想:技术团队需要自己的监控技术和平台。
感想:需要数据的支撑
结合fabric
总结一下:
开发阶段可以采用精度更高的msgSend的方案。卡顿监控能够上线的方案最稳妥的应该还是runloop 配合fps+cpu 双参数 配合fabric(自己公司使用的堆栈上传系统)的方式比较适合,但是要落地到生产环境还是要慎重。
写在最后:
Better Late Than Never ,愿我们都能跨出自己的第一步。
站在巨人的肩膀上,感谢前辈们的文章。
参考链接:
https://juejin.im/post/59edb7596fb9a0450d103f34
https://juejin.im/entry/5bdfdc9951882516ca07c8ae 利用fabric上报
https://gist.github.com/hite/1a7ee47fd971acad3e9e99b41c41c82e
https://tech.meituan.com/2016/12/19/hertz.html Hertz
https://my.oschina.net/KeepDoing/blog/1921631
https://www.geekpeer.com/Development/ios/4161.html
https://tech.meituan.com/2016/12/19/hertz.html
https://www.jianshu.com/p/04576c975c4d 方案总结
https://juejin.im/post/5bb09795f265da0ac84946e0 方案总结
https://wereadteam.github.io/2016/05/03/WeRead-Performance/
https://blog.csdn.net/u010262501/article/details/79616963
https://blog.csdn.net/Hello_Hwc/article/details/52331548
http://www.tanhao.me/code/151113.html/
https://www.ctolib.com/CMainThreadDetector.html
https://cloud.tencent.com/developer/article/1030608
runloop 示例
https://github.com/Haley-Wong/RunLoopDemos/blob/master/RunLoopDemo03/RunLoopDemo03/FluencyMonitor.m
https://blog.gocy.tech/2019/07/08/hook-msgSend-advance/
https://zsisme.gitbooks.io/ios-/content/chapter4/visual-effcts.html